注记
dither
硬件工程
shell
htap
位运算
取代LABVIEW
SpringMVC的常见注解
safari
网页作业
python自动化测试
DSP
BP神经计算
SoftReference
WordPress标签
数据增强
web期末网页作业
maya
高等数值计算方法
时间戳
深入双数组Trie(Double-Array Trie)
cle_content" class="article_content clearfix">
content_views" class="htmledit_views">
class="entry-more">
c" class="toc ">
chives/2009/04/editor-content.html?cs=utf-8" name=".E4.BB.80.E4.B9.88.E6.98.AFDouble_Array_Trie">
 class="mt-image-left" alt="256x_tree.png" src="http://my.huhoo.net/archives/assets_c/2009/04/256x_tree-thumb-400x192.png" width="400" height="192" style="margin:0pt 20px 20px 0pt; float:left" />
class="mt-image-left" alt="256x_tree.png" src="http://my.huhoo.net/archives/assets_c/2009/04/256x_tree-thumb-400x192.png" width="400" height="192" style="margin:0pt 20px 20px 0pt; float:left" />
 class="mt-image-left" alt="dat.png" src="http://my.huhoo.net/archives/assets_c/2009/04/dat-thumb-400x213.png" width="400" height="213" style="margin:0pt 20px 20px 0pt; float:left" />
class="mt-image-left" alt="dat.png" src="http://my.huhoo.net/archives/assets_c/2009/04/dat-thumb-400x213.png" width="400" height="213" style="margin:0pt 20px 20px 0pt; float:left" />
 class="mt-image-left" alt="trie.png" src="http://my.huhoo.net/archives/assets_c/2009/04/trie-thumb-550x380.png" width="550" height="380" style="margin:0pt 20px 20px 0pt; float:left" />
chives/2009/04/editor-content.html?cs=utf-8" name="DAT.E6.94.B9.E8.BF.9B.E6.96.B9.E6.A1.88">
class="mt-image-left" alt="trie.png" src="http://my.huhoo.net/archives/assets_c/2009/04/trie-thumb-550x380.png" width="550" height="380" style="margin:0pt 20px 20px 0pt; float:left" />
chives/2009/04/editor-content.html?cs=utf-8" name="DAT.E6.94.B9.E8.BF.9B.E6.96.B9.E6.A1.88">
 class="mt-image-left" alt="reversedat.png" src="http://my.huhoo.net/archives/assets_c/2009/04/reversedat-thumb-550x237.png" width="550" height="237" style="margin:0pt 20px 20px 0pt; float:left" />
class="mt-image-left" alt="reversedat.png" src="http://my.huhoo.net/archives/assets_c/2009/04/reversedat-thumb-550x237.png" width="550" height="237" style="margin:0pt 20px 20px 0pt; float:left" />
|
|
- Double Array Trie是TRIE树的一种变形c;它是在保证TRIE树检索速度的前提下c;提高空间利用率而提出的一种class="tags" href="/tags/ShuJuJieGou.html" title=数据结构>数据结构c;本质上是一个确定有限自动机(deterministic finite automatonc;简称DFA)。
- 所谓的DFA就是一个能实现状态转移的自动机。对于一个给定的属于该自动机的状态和一个属于该自动机字母表Σ的字符c;它都能根据事先给定的转移函数转移到下一个状态。
chives/2009/04/editor-content.html?cs=utf-8" name="DAT.E5.AE.9A.E4.B9.89">
- DAT是采用两个线性数组(base[]和check[])c;base和check数组拥有一致的下标c;(下标)即DFA中的每一个状态c;也即TRIE树中所说的节点c;base数组用于确定状态的转移c;check数组用于检验转移的正确性。因此c;从状态s输入c到状态t的一个转移必须满足如下条件:
base[s] + c == t check[base[s] + c] == sclass="mt-enclosure mt-enclosure-image" style="display:inline">
- 图中最顶端有256的父节点c;每个父节点都有256个子节点;那么无论汉字和字母c;都可以分布在256个子节点上c;但是如果词语只有app和class="tags" href="/tags/APPLE.html" title=apple>apple以及banana三个词语c;那么256个父节点显得有些浪费c;实际上只需要2个父节点就可以了。
基于上述定义c;DAT的匹配过程如下:假设当前状态为sc;对于输入的字符c有:
t = base[s] + c; if check[t] = s then next state = t; else fail; endif
DAT匹配的过程相对简单c;很容易理解。
chives/2009/04/editor-content.html?cs=utf-8" name="DAT.E6.9E.84.E9.80.A0">- 首先我们需要了解一下DAT的内存管理
- 在DAT的构造过程当中c;一般有两种构造方法:
- 已知所有词语c;静态构造双数组;
- 动态输入词语c;动态构造双数组。
- 当n条词语准备构建双数组时c;先以添加一条词语color:red">cat为例c;双数组中base[1024]数组根节点为0(默认值c;当然根据“个人爱好”可以随意指定)c;下标为0c;为词语cat的首字符"c“(99)找一个合适的位置c;比如位置100c;即:
-
base[0] = 100;
- 此处那么在base[100]的位置下c;加上字符"c"的ascii值得到下一个状态(t)的位置(199)c;然后在一个合适的位置(空闲的位置)197c;使得
-
base[199]+'a'=197;
- 那么状态(t)c;即base[199]的值可以通过上述公式得到仍然为100
- 值得注意是c;在状态(f)c;目前即字符"t"c;结束时c;其value值可以做如下处理c;如果状态(f)结束c;没有子节点c;则
-
base(f)=-1 * f;
- 如果状态(t)结束c;仍然有多个子节点c;那么其base数组标记为
-
base(f)=-1 * base(f);
- 当输入第二条词语color:red">camera时c;仍然按照上述方式进行c;当进行到字符a时c;字符a位置的下标为197c;检查check[base[197]+'m']是否为空位。
- 如果为空位c;则base[197]的值仍然可以为100;
- 否则需要重新寻找两个空位位置Ψ(base[197]+'m')c;λ(base[197]+'t')c;使得 base[base[197]+'m']=-1(-1标记为空位状态c;"m"为camera的第三个字符)和 base[base[197]+'t']=-1("t"为cat的第三个字符)c;即第二级节点a后面的两个新节点能有位置存放新的偏移量c;并使得 check[base[197]+'m']=197和check[base[197]+'t']=197即可c;那么base[197]的值需重新指向到新的位置(Ψ+λ-'m'-'t')/2。
- 接着继续重新构建下面新两个节点的DAT结构c;且第一个节点的结构构造完成后c;需要清除原来的构建。
- 动态构造双数组能够很方便的动态插入词语c;不需要重新构造整个TRIE树c;但是实现的逻辑相对复杂一些。
- 若初始状态申请的数组大小不足时c;需要进行扩充c;并将原来的数组拷贝到新增大的数组上c;且原来的数组一般需要进行内存释放c;如下图:
- 在DAT的构造过程当中c;一般有两种构造方法:
- DAT相对普通TRIE树来说c;提高了空间的利用率c;但是空间利用率还不是最好的。
- 比如单词elephant(8个字符)c;如果所有词语当中只有一个以e开头的词语c;一般我们实现trie的结构写成
class="tags" href="/tags/STRUCT.html" title=struct>struct BC_st { int base; int check; };
- 那么整个词语在DAT中占用的空间是4*2*8=64字节。其实class="tags" href="/tags/CunChu.html" title=存储>存储没有必要浪费那么多空间c;在DAT结构里面c;完全可以以7个字节来class="tags" href="/tags/CunChu.html" title=存储>存储lephantc;查询的时候lephant实现字节查找就可以了。
- DAT是一个树型的结构c;不断发散的结构c;如果在对面实现一个同样的结构c;相对来说c;会减少一半的空间体积c;如图所示:
- http://linux.thai.net/~thep/datrie/datrie.html
相关文章
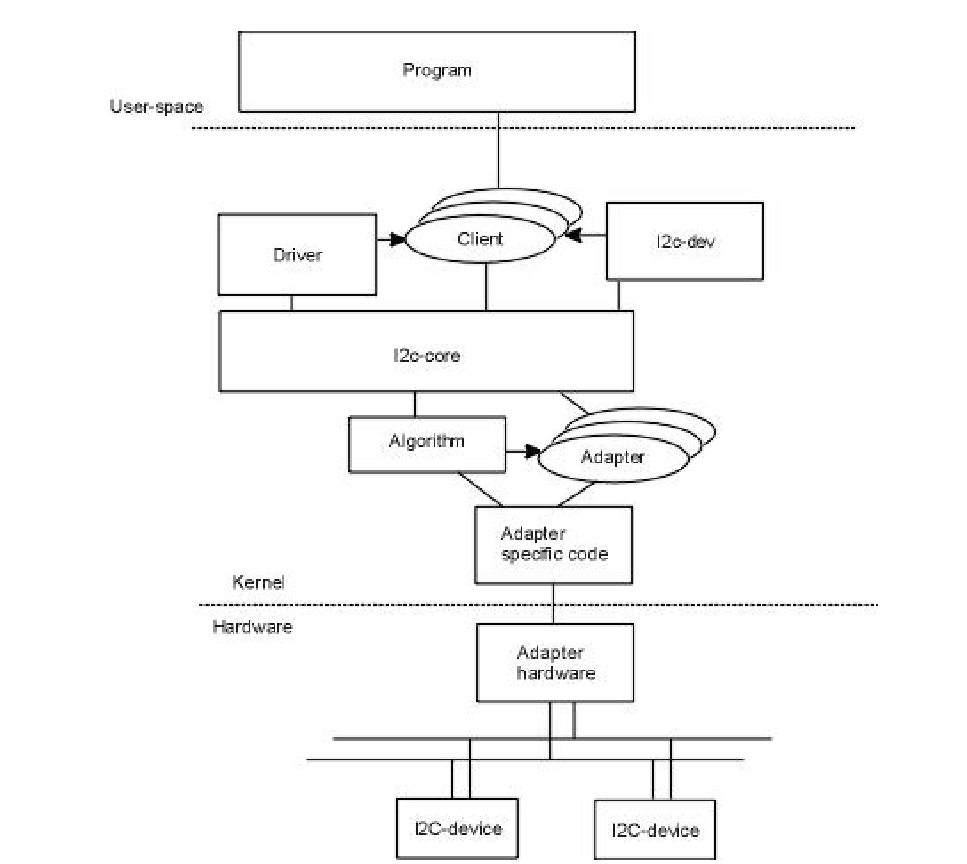
4-Linux i2c system
Linux i2c system I2C总线是由PHILIPS公司开发的两线式串行总线,每个连接到总线的器件都可以通过唯一的地址和主机主机进行通讯,主机可以作为主机发送器或主机接收器;串行的8位双向数据传输位速率在标准模式下可达100kbit/s,快速模…

LuaFramework内存资源管理器ResourceManger详解及切换场景资源清理
1.成员变量m_BaseDownloadingURL : 获取资源的地方,加载AssetBundle包的时候会用到m_AssetBundleManifest : 包间依赖关系文件,从这个类中的信息中可以知道某个包依赖的包有哪些,如果依赖的包还没加载进去则先加载依赖…
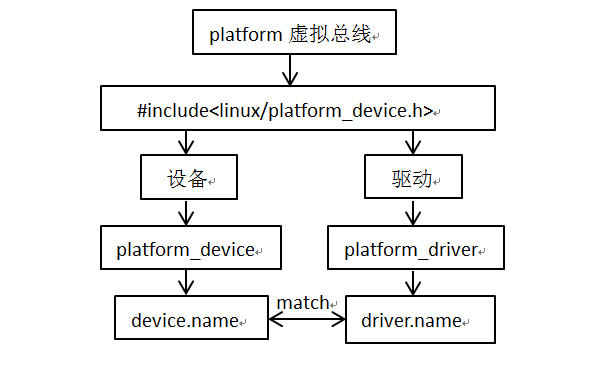
3-Linux platform system
Linux platform system platform是Linux内的一种虚拟总线,称为platform总线,相应的设备称为platform_device,而驱动称为platform_driver。platform总线、设备和驱动这3个实体,总线将设备和驱动绑定,在系统每注册一个设…

VS2015修改项目名称
本需求:在同一个解决方案中。因为要在另一个项目的基础上添加功能,而之前的项目同时存在。相当于是分支开发。 第一方案:采用项目模板形式,做了以后,发现少了很多东西。因为我是C项目。查了资料,原来C项目…

python自动华 (八)
Python自动化 【第八篇】:Python基础-Socket编程进阶 本节内容: Socket语法及相关SocketServer实现多并发1. Socket语法及相关 sk socket.socket(socket.AF_INET,socket.SOCK_STREAM,0) 参数一:地址簇 socket.AF_INET IPv4(默…
基于双数组trie树的中文分词程序
由于前面写的朴素bayes分类器,针对英文文本进行统计分析的,现在要想用于中文文本,则需要对中文文本进行分词。找了好几个分词系统,比如张华平老师的ICTCLAS、吕震宇老师用c#改写的ICTCLAS版本、KTDictSeg分词系统V1.3.01和清华王小…
1-Openwrt clone and bulid
Openwrt clone and bulid Openwrt是一个高度模块化、高度自动化的嵌入式Linux系统,拥有强大的网络组件和扩展性,常常被用于工控设备、电话、小型机器人、智能家居、路由器以及VOIP设备中。为了更加深入的了解Openwrt,我们从最直接的学习方式开…
Oracle获取表、视图的所有字段说明
当前需要获取一个视图的所有字段。 查了资料,发现,表及视图的结构信息都有。:
all_tab_cols / all_tab_columns 查看所有用户下的表及视图结构
user_tab_cols / user_tab_columns 查看当前用户下的表及视图结构
user_col_comments 查看当前…
最新文章
- 【C++】【MFC】绘图
- 信息系统项目管理师【一】英文选择题词汇大全(2)
- 用PlantUML和语雀画UML类图
- 如何构建数据驱动的企业?爬虫管理平台是关键桥梁吗?
- 【FreeRTOS】configLIBRARY_MAX_SYSCALL_INTERRUPT_PRIORITY宏解析
- 学懂C#编程:C# 索引器(Indexer)的概念及用法
- 视频监控业务平台LntonCVS视频监控管理平台智慧机场视频监控应用方案
- ActiveRecord’s queries tricks 小记
- php 多线程pthreads官网翻译
- Vue超快速学习
- 开机过程中的内核打印
- .NET Framework Security Code Access Security-應用程式篇
- [C#]I/O完成端口的实现